Chart: A New Way to Deploy High-Performant ML Models Machine learning (ML) models are becoming more and more popular in various domains, such as computer vision, natural language processing, and recommender systems. However, deploying ML models into production is not an easy task. It requires a lot of engineering skills and resources to optimize the model performance, scalability, and reliability.
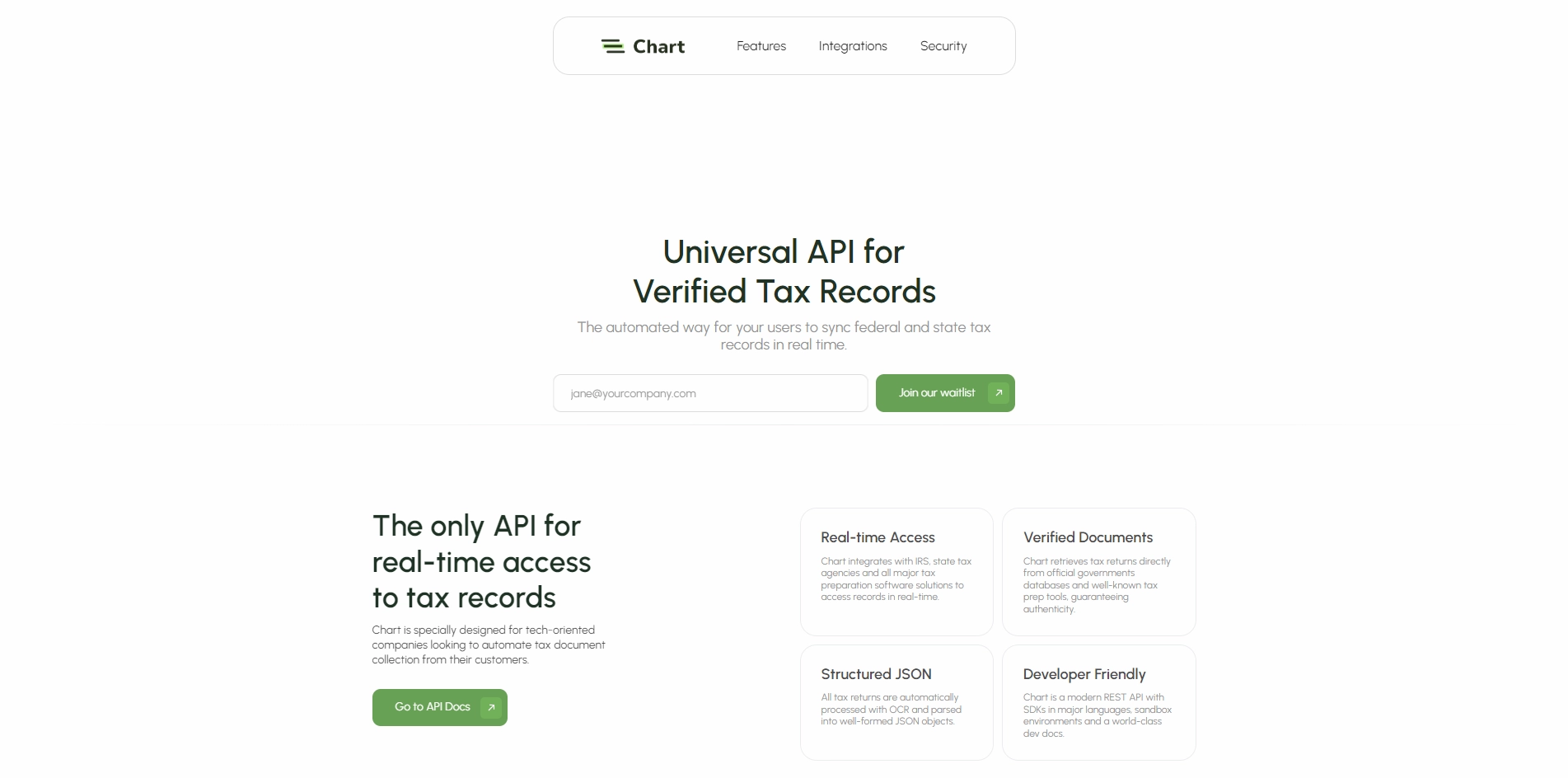
That's where Chart comes in. Chart is a new startup that aims to simplify the ML deployment process. Chart packages your models into high-performant C++ servers and deploys them into your own cloud account. You don't need to worry about the complexities of MLOps, such as model conversion, optimization, testing, monitoring, and scaling. Chart handles all of that for you.
How does Chart work? Chart transforms your ML models into CUDA/HIP optimized C++ code for lightning-fast inference. You can use any framework or library to train your models, such as TensorFlow, PyTorch, or Scikit-learn. Then, you simply integrate your cloud provider (such as AWS, Azure, or Google Cloud) and Chart deploys fast, auto-scaling inference servers in your own cloud account. You can access your models via REST API or gRPC.
What are the benefits of using Chart? Chart offers several advantages over other ML deployment solutions:
- Speed: Chart uses C++ and CUDA/HIP to optimize your models for GPU/CPU inference. This can result in up to 10x faster inference than Python-based solutions.
- Cost: Chart deploys your models in your own cloud account, so you only pay for what you use. You can also leverage spot instances or preemptible VMs to reduce your cloud costs even further.
- Control: Chart gives you full control over your ML deployment. You can monitor your model performance, logs, and metrics via a web dashboard. You can also update or rollback your models with a single click.
- Security: Chart ensures that your models and data are secure and compliant. You can use encryption, authentication, and authorization to protect your API endpoints. You can also use custom domains and SSL certificates to enable HTTPS.
Chart is currently in beta and accepting requests for early access. If you are interested in trying out Chart for your ML deployment needs, you can sign up on their website: https://www.getcharteditor.com/
Key Platforms
Core Service Areas:
Seamless Model Deployment
Optimized Performance
Scalability Solutions
Robust Reliability
User-Friendly Interface
Comprehensive Analytics
Pros
- It allows users to deploy high-performant ML models with ease.
- It transforms ML models into CUDA/HIP optimized C++ code for lightning-fast inference.
- It deploys fast, auto-scaling inference servers in the user's own cloud account.
- It abstracts away all the complexities of MLOps.
- It is backed by Y Combinator, a prestigious startup accelerator.
Cons
- It is still in beta stage and requires access request.
- It may not support all types of ML models or cloud providers.
- It may have bugs or security issues that are not yet discovered or fixed.
Frequently Asked Questions About Chart
01
What is Chart and how does it help with ML model deployment?
Chart is an AI tool designed to simplify the deployment of high-performing machine learning models. It streamlines the process, making it easier for users to optimize model performance, scalability, and reliability without requiring extensive engineering skills.
02
Which types of ML models can be deployed using Chart?
Chart supports a wide range of machine learning models, including those used in computer vision, natural language processing, and recommender systems, ensuring versatility for various applications.
03
Do I need technical expertise to use Chart?
No, Chart is designed to be user-friendly and does not require extensive technical expertise. It provides tools and resources that enable users with varying levels of experience to deploy ML models effectively.
04
What are the key features of Chart?
Key features of Chart include model optimization for performance, scalability, and reliability, as well as an intuitive interface that facilitates easy deployment and management of machine learning models.
05
Is there support available if I encounter issues while using Chart?
Yes, Chart offers customer support to assist users with any issues they may encounter, ensuring a smooth experience while deploying and managing their machine learning models.
Promote Chart
Get Chart in front of thousands of buyers actively searching for AI tools. Feature your listing on the homepage and category pages, or add the verified badge to your site.
Copy Embed Code
Share on
Related AI Tools
Explore related AI tools for diverse applications and enhanced productivity
Unlock the best AI Tools for you!
Login or Approve this tool to continue exploring features and analytics.
Login to unlock the best AI Tools for you!
By proceeding, you agree to our Terms of use and confirm you have read our Privacy and Cookies Statement.
Subscribe Newsletter
Subscribe to our AI Tools Newsletter for exclusive insights, cutting-edge innovations, and the latest AI advancements delivered straight to your inbox!